在上一部分探讨了海量数据处理系统的基础理念与挑战后,我们将视角转向其核心——系统架构与关键技术创新。阿里巴巴作为全球电商与云计算巨头,其内部数据处理产品历经“双十一”等极限场景锤炼,形成了一套独特而高效的设计哲学。本文将从架构演进与创新技术两个维度,剖析阿里系产品如何驾驭数据洪流。
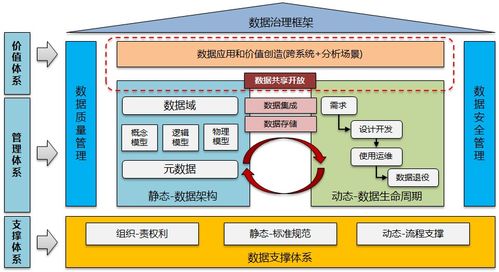
一、 分层解耦与流批一体的架构演进
阿里海量数据处理系统的架构设计,深刻体现了“分而治之”与“弹性扩展”的思想。其典型架构通常分为以下几层:
- 数据采集与接入层: 通过自研的DataX、Canal等工具,实现异构数据源(数据库、日志、IoT设备)的全量与增量同步,确保数据“滴水不漏”地汇入系统。这一层强调高吞吐、低延迟与端到端的精确性。
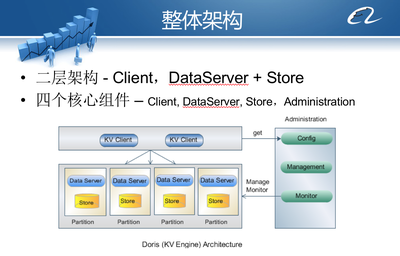
- 计算引擎层: 这是系统的“大脑”。阿里早期基于Hadoop生态构建,随后为满足实时性需求,大力发展流计算(如Blink,后贡献给Flink社区)。最大的架构创新在于提出并实践了“流批一体”理念。以MaxCompute(离线计算)和Flink(实时计算)为核心,通过统一的数据模型(如Apache Calcite的SQL层)和运行时环境,让同一套业务逻辑既能处理历史数据,也能处理实时流数据,极大简化了开发运维复杂度,并保证了数据处理结果的一致性。
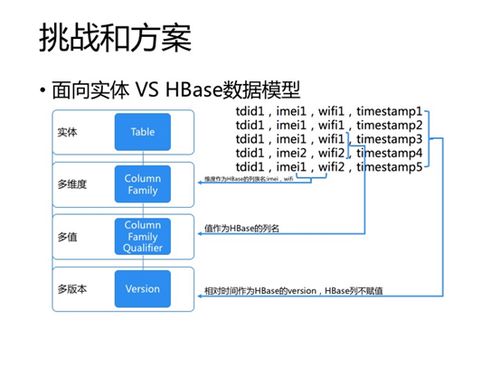
- 存储层: 采用混合存储策略。对于海量冷数据,使用成本低廉、高可靠的分布式对象存储OSS;对于需要频繁交互分析的温/热数据,则采用高性能的表格存储Tablestore、AnalyticDB等。通过数据湖架构(如阿里云Data Lake Formation)统一管理元数据,实现数据在多种存储间的自由流动与无缝访问。
- 数据服务与管理层: 包括数据开发平台(如DataWorks)、数据资产管理、数据安全与治理体系。这一层将技术能力产品化、可视化,让数据工程师和业务分析师能够高效协同,并确保数据质量、安全与合规。
二、 驱动效率革命的关键技术创新
在具体技术实现上,阿里的内部产品围绕“更快、更稳、更省”持续突破:
- 计算性能的极致优化:
- 编译优化与向量化执行: 对SQL等高级语言进行深度编译优化,生成高度优化的底层执行代码,并利用CPU的SIMD指令集进行向量化计算,大幅提升单机处理性能。
- 智能调度与资源优化: 基于混部技术与先进的调度算法(如基于AI的调度器),在超大规模集群上实现数百万计算任务的精细调度,最大化资源利用率,缩短作业执行时间。
- 存储与成本的精细把控:
- 自适应存储格式与索引: 根据数据访问模式自动选择列存、行存或混合存储格式,并构建智能索引,加速查询的同时减少存储开销。
- 分层存储与智能冷热分离: 自动识别数据热度,将其在不同性能/成本的存储介质间迁移,实现存储成本的整体最优。
- 可靠性与可用性的基石:
- 端到端的一致性保证: 在分布式环境下,通过分布式事务、流处理中的精确一次(Exactly-Once)语义等技术,确保数据处理不丢不重,结果准确可信。
- 全链路容灾与多活: 从数据同步、计算到服务,构建同城双活、异地多活的高可用架构,保障即使单个数据中心故障,核心数据业务也不中断。
- 智能化与自治运维:
- AI for Data: 将机器学习应用于数据管理本身,实现智能调优(如自动优化SQL)、异常检测(如数据质量监控)、根因分析等,降低运维负担。
- Serverless化: 提供完全托管的Serverless数据处理服务,用户无需关心底层基础设施,按实际使用的计算和存储资源付费,真正实现弹性伸缩与成本可控。
从阿里内部产品的实践中可以看出,现代海量数据处理系统的设计,已从单纯追求规模扩展,演进到对架构统一、性能极致、成本精细和运维智能的综合考量。“流批一体”的架构范式与持续深化的技术创新,共同构成了应对数据爆炸时代的核心引擎。对于提供信息技术咨询服务的企业与专家而言,理解这些来自超大规模实践的前沿理念与技术趋势,对于帮助企业构建高效、敏捷、经济的数据平台,驱动数字化转型,具有至关重要的借鉴与指导意义。未来的系统,必将在云原生、智能化与开放协同的方向上继续深化,让数据价值的挖掘变得更简单、更强大。