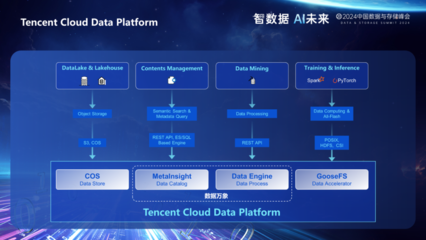
Apache软件基金会宣布,Apache InLong成功从孵化器毕业,正式成为顶级项目(Top-Level Project)。这一里程碑事件标志着InLong在数据集成与流处理领域的技术成熟度与社区认可度达到了新的高度。作为一款面向大规模数据场景的一站式数据集成平台,InLong的核心亮点在于其宣称的“百万亿级数据流处理能力”。本文将深入解读其背后的技术架构与关键特性,探讨其如何支撑起如此庞大的数据处理规模。
一、架构概览:一体化与模块化设计
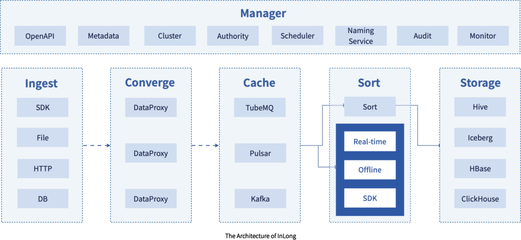
Apache InLong的核心设计理念是“一体化”。它旨在简化数据从接入、传输到处理、分发的全链路流程,将数据摄取、数据传输、数据同步、数据转换以及数据订阅等功能融为一体。这种“一体化”并非臃肿的 monolithic 架构,而是通过清晰的模块化设计实现的。其主要组件包括:
- InLong Manager: 统一的管控中心,负责元数据管理、工作流编排、系统配置和用户权限控制,提供了数据流的“声明式”定义与管理能力。
- InLong Agent: 轻量级、高可扩展的数据采集代理。支持从多种数据源(如日志文件、Kafka、MySQL binlog、Pulsar等)实时拉取或推送数据,并具备强大的容错与负载均衡能力,是海量数据接入的基石。
- InLong DataProxy: 高性能的数据代理层。作为Agent与后端消息队列之间的桥梁,它负责协议的转换、数据的聚合与路由,并对流量进行管控,有效缓冲上游的写入压力,提升系统整体吞吐量。
- InLong Sort: 基于Apache Flink构建的流式数据处理核心。它从DataProxy下游的消息队列(如Apache Pulsar, Apache Kafka)中消费数据,进行实时ETL、聚合计算,并将结果分发给各类数据存储(如ClickHouse, Hive, HBase, Kafka等)。Sort模块是支撑复杂流处理逻辑与百万亿级计算能力的关键。
这种分层、解耦的架构使得各个组件可以独立扩展,为应对数据规模的指数级增长提供了灵活的弹性。
二、实现百万亿级处理能力的关键技术亮点
1. 高性能、低延迟的传输链路:
InLong的数据通路(Agent -> DataProxy -> MQ -> Sort)经过深度优化。DataProxy采用异步化、批处理与连接复用技术,极大提升了网络I/O效率。其对Apache Pulsar和Kafka等高性能消息队列的原生深度集成,确保了数据在传输层的超高吞吐与低延迟。
2. 强大的流处理引擎(Sort):
基于Apache Flink,InLong Sort继承了其高吞吐、Exactly-Once语义、状态管理和窗口计算等核心优势。更重要的是,InLong团队对Flink进行了大量生产级别的增强与适配,包括:
- 动态扩缩容: 支持根据数据流量动态调整计算资源,实现成本与性能的平衡。
- 多租户与资源隔离: 确保不同业务或团队的数据流任务互不干扰,稳定运行。
- 高效的上下游连接器: 针对各种数据源和存储,优化了连接器的性能与稳定性,减少数据流转瓶颈。
3. 智能的负载均衡与容错机制:
在Agent和DataProxy层,系统能够实时感知节点负载与网络状况,动态调整数据分发策略,避免热点问题。任何组件的故障都能被快速检测并触发自动切换或数据重传,保障数据流服务的持续可用性与数据完整性。
4. 声明式与自动化运维:
通过InLong Manager提供的RESTful API和控制台,用户可以像编写配置文件一样,通过简单的JSON或SQL语句声明数据流的源、目标、转换逻辑和运行策略。系统随后自动完成资源的申请、任务的部署与监控,极大降低了管理和维护超大规模数据流水线的复杂性。
5. 端到端的数据治理与可观测性:
InLong内置了完善的数据审计、质量监控和指标度量体系。用户可以实时追踪每条数据流的吞吐量、延迟、错误率,并能追溯到具体的数据链路,为百万亿级数据处理的稳定性与可靠性提供了坚实保障。
三、与展望
Apache InLong从孵化到毕业,其核心价值在于将大数据生态中分散、复杂的组件(采集、传输、计算、存储)整合为一个协调、高效、易用的整体解决方案。其宣称的“百万亿级数据流处理能力”并非空中楼阁,而是建立在模块化可扩展架构、深度优化的高性能组件、强大的Flink计算引擎以及智能的自动化运维体系之上。
随着正式成为Apache顶级项目,InLong将获得更广泛的社区关注与合作,其生态兼容性(支持更多数据源与目的地)、云原生部署体验以及流批一体能力的深化,将是未来发展的关键方向。对于面临海量数据实时集成与处理挑战的企业而言,Apache InLong无疑提供了一个极具吸引力的、经过Apache社区验证的新选择,有望推动行业进入更高效、更简洁的百万亿级数据处理新纪元。