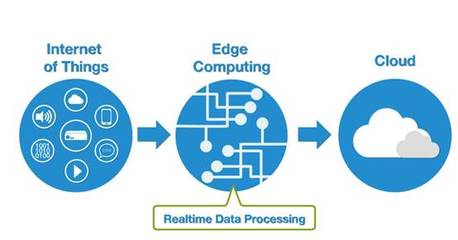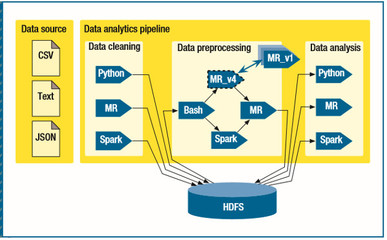
随着大数据技术的快速发展,企业数据环境日益复杂,异构数据源、多样化计算框架和存储系统成为常态。在这样的背景下,构建高效、可靠的数据管道至关重要,它不仅能实现数据的流畅流转,还能为上层应用提供统一的数据处理和存储服务。
一、异构大数据环境的挑战与需求
异构大数据运行环境通常包括多种数据源(如关系型数据库、NoSQL数据库、日志文件、实时流数据等)、不同的计算引擎(如Hadoop、Spark、Flink)以及多样化的存储系统(如HDFS、对象存储、云数据库)。这种多样性带来了数据格式不一致、系统集成复杂、性能优化困难等挑战。因此,构建数据管道需满足以下核心需求:统一的数据接入与转换、弹性可扩展的架构、低延迟高吞吐的数据处理,以及安全可靠的数据存储。
二、数据管道的构建策略与关键技术
- 数据接入与集成:采用统一的数据接入层,支持批量和实时数据采集。例如,使用Apache Kafka或Flume作为数据总线,实现多源数据的实时摄取。通过数据格式转换工具(如Apache NiFi或自定义ETL脚本)将异构数据标准化为统一格式,便于后续处理。
- 数据处理与计算:根据业务需求选择合适的计算框架。对于批量处理,可结合Hadoop或Spark进行分布式计算;对于实时流处理,可采用Flink或Storm。引入数据清洗、去重、聚合等操作,确保数据质量。在异构环境中,容器化技术(如Docker和Kubernetes)能有效管理不同计算任务的资源调度,提升管道弹性。
- 数据存储与服务化:构建分层存储体系,将原始数据、中间结果和最终数据分别存储于不同系统中。例如,原始数据存入HDFS或云对象存储,处理后的数据存入关系型数据库或NoSQL数据库(如HBase、Cassandra)以供查询。通过API网关或数据服务层,对外提供统一的数据访问接口,支持应用程序的实时调用和数据分析。
三、数据处理与存储服务的优化实践
为提升数据管道的整体性能,需关注以下优化点:实施数据分区与索引策略,加快查询速度;利用缓存机制(如Redis)减少对后端存储的频繁访问;通过监控和告警系统(如Prometheus和Grafana)实时跟踪管道健康状况,及时发现并解决瓶颈问题。
四、未来展望
随着人工智能和边缘计算的兴起,异构大数据环境将更加复杂。数据管道需向智能化、自适应方向发展,例如引入机器学习算法自动优化数据处理流程,并支持边缘设备的数据集成。数据安全和合规性将成为重点,需在管道中嵌入加密、审计等机制。
构建面向异构大数据环境的数据管道是一个系统工程,需综合考虑数据接入、处理、存储和服务化等多个环节。通过采用先进的技术和优化策略,企业能够实现数据的高效流动与价值最大化,为业务创新奠定坚实基础。